This is only covered partially in other places. To prevent changing themes/stationary and also reverting existing themes/stationary push all four of the below keys via GPO.
Create REG_SZ values
HKEY_CURRENT_USER\SOFTWARE\Microsoft\Office\16.0\Common\MailSettings
“NewStationery”=””
“NewTheme”=””
HKEY_CURRENT_USER\Software\Policies\Microsoft\office\16.0\common\mailsettings
“NewStationery”=””
“NewTheme”=””
You should be seeing the settings page at “Computer Configuration –> Administrative Templates –> Control Panel” with the name “Settings Page Visibility” within Server 2016, but you don’t. :sadpanda:
To resolve:
– Apply all cumulative updates, this first appeared in the September 2018 update
– Copy ControlPanel.adml from C:\Windows\PolicyDefinitions\en-US\ and ControlPanel.admx from C:\Windows\PolicyDefinitions to the same folders in your central repository (if you are using one) at \localhost\sysvol\<domain name>\Policies\PolicyDefinitions\ and \en-US.
– Close, reopen GPO mgmt console
Thanks to
https://www.carlstalhood.com/group-policy-objects-vda-user-settings/#settingspag
for helping me find the answer.
When checking in extension ‘Data Loss Prevention 11.0 Patch 6 ePO extension’ I receive the error:
Command Failed: Missing dependencies are required by extension UDLPSRVR2013: commonui-core-common:1.3.0 commonui-core-rest:1.3.0. Ensure these extensions and minimum versions are installed..
Failed to check in extension ‘Data Loss Prevention 11.0 Patch 6 ePO extension’.
I was unable to find these commonui-core extensions under the mcafee download site, nor in my software manager.
To resolve, within the McAfee download site at https://www.mcafee.com/content/enterprise/en-us/downloads/my-products/downloads.html, download one of the extensions named “McAfee Data Loss Prevention ePO extension Version 11.x” (should work for 11.0 and 11.1 at least). Within this package you will find mfs-commonui-core-common-1.3.0.258.zip and mfs-commonui-core-rest-1.3.0.258.zip.
After installing these two extensions, you will now be able to install the DLP extension for 11.x.
To resolve
- upgrade license in vmware license portal to version 6
- within vcenter > home > administration > license > add the license
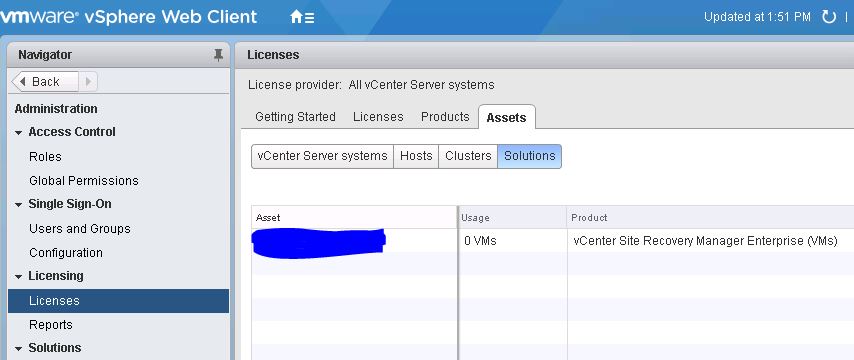
- Click on the assets tab > solutions button > right click on SRM solution > assign license
The step about assigning the license in the assets tab is wrong on all VMware documentation I have read, which led me to having to call support to resolve.
On a VNX 5300 array, after powering down, unseating, and re-seating a SP I encountered the event code 0x7241 with warning message “Valid SP-Cache is for Storage Processor SP…”.
Disabling write and read caches on each SP did not resolve. Restarting management services on the SPs did not resolve.
To resolve, I restarted one SP within the Unisphere GUI, then after it was back up, I restarted the other SP.
So there were plenty of licenses, what else can be wrong?
Within the log files @ C:\ProgramData\VMware\VMware vCenter Site Recovery Manager\Logs I saw the following:
2016-04-06T15:38:31.479-05:00 [09472 warning ‘Licensing’] Unable to decode license ”: INVALID_SERIAL
2016-04-06T15:38:31.480-05:00 [07916 info ‘Licensing’] Initializing with license key:
2016-04-06T15:38:31.480-05:00 [07916 verbose ‘PropertyProvider’] RecordOp ASSIGN: asset, DrLicenseManager
2016-04-06T15:38:31.480-05:00 [07916 warning ‘Licensing’] The license key ” expired on 1970-01-01T00:00:00Z
2016-04-06T15:38:31.481-05:00 [09240 warning ‘Licensing’] This SRM instance is no longer in compliance. 41 4(s) are not licensed for protection.
In the web client under home > licensing > solutions I found something that didn’t exactly refer to SRM but I assigned the SRM key to it anyways. After assigning this key the problem was resolved.
To prevent click-jacking, add the HTTP response header “X-Frame-Options” into IIS for websites and or Exchange OWA:
– Open IIS Manager and click on the server name in the left column. Drill down if you only want to apply to one website.
– In Features View, double-click HTTP Response Headers.
– On the HTTP Response Headers page, in the Actions pane, click Add.
– In the Add Custom HTTP Response Header dialog box, add a header called “X-FRAME-OPTIONS”, and assign it’s value to “SAMEORIGIN”.
– Click OK
You can validate correct function by visiting one of these websites:
https://securityheaders.io
http://web-sniffer.net/
I was unable to find this problem documented anywhere, though there was a reference to it on another blog here: http://www.virtualmachinery.co.uk/2015/03/upgrading-site-recovery-manager-55-to.html
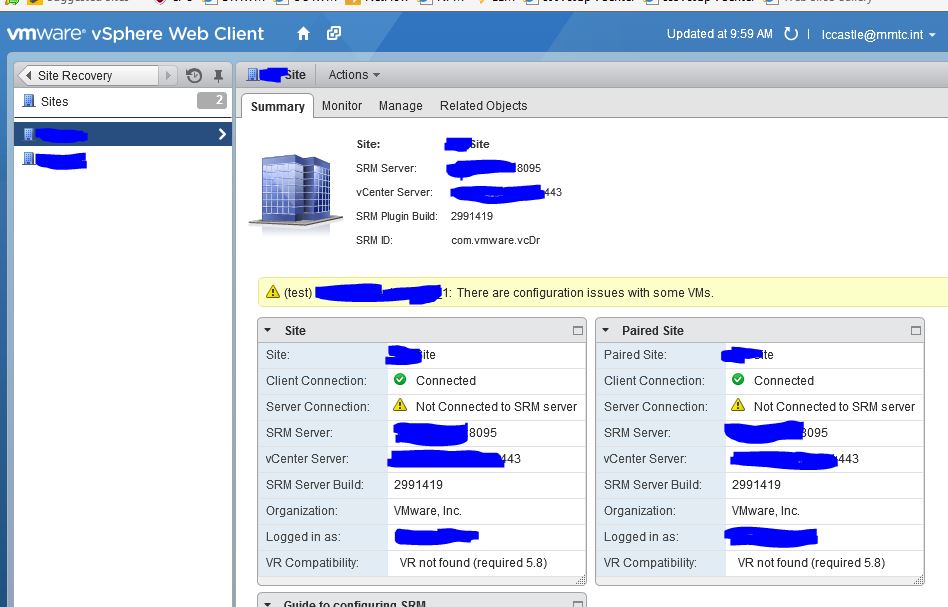
The problem presents itself this way, looking at SRM in the web client in version 5.5 of VMWare, 5.8.1 of SRM:
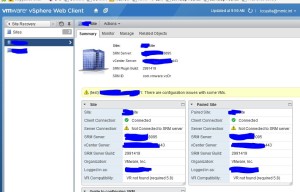
As you can see, client connection shows as connected, however server connection shows as “Not Connected to SRM server”. It wasn’t obvious to me, but what this means is the sites are not connecting to each other, even though they are paired and everything else looks green.
Additionally you will notice that the option to replicate changes to the secondary site before failover will be grayed out.
I spent several days troubleshooting this before I found an indicator in the logs that pointed to certificate errors. I believe that if I was able to un-pair and then re-pair the sites, this would have been resolved. However in order to un pair sites, you must first delete the recovery plans and protection groups. When attempting to delete, the status would say deleting and never complete.
Ultimately to resolve I uninstalled SRM at both sites, deleting all data from database. I then reinstalled and reconfigured SRM, protection groups, and recovery plans.
Edit: According to Jim in the comments, there is a better way – confirmed by multiple people.
*.ade
*.adp
*.arj
*.asx
*.bas
*.bat
*.cab
*.chm
*.cmd
*.com
*.cpl
*.crt
*.exe
*.hlp
*.hta
*.inf
*.ins
*.jar
*.js
*.jse
*.jsp
*.lib
*.lnk
*.mdb
*.mde
*.msi
*.msp
*.nsc
*.pcd
*.pif
*.pptm
*.ps1
*.reg
*.rwa
*.scr
*.sct
*.shs
*.vb
*.vbe
*.vbs
*.wmd
*.wsc
*.wsf
*.wsh
Additionally you may consider scanning these closer, quarantining, or blocking:
*.rar (block any that are encrypted/can not be scanned)
*.zip (block any that are encrypted/can not be scanned)
*.pdf (block any that are encrypted/can not be scanned)
*.xlsm (macro enabled xls)
*.docm (macro enabled docs)
*.doc (block any that are macro enabled if possible)