SAN errors, oh no!
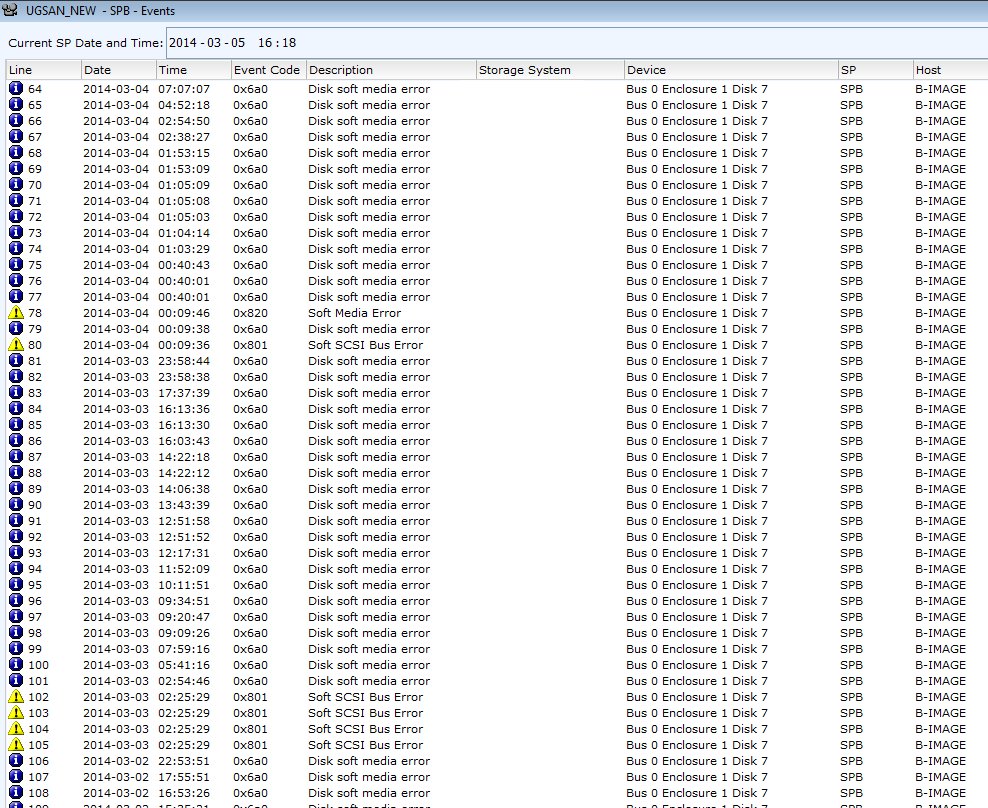
The process started when the array emailed me a couple of soft media errors, so I glanced at the SPA and SPB event logs in Navisphere and saw this:
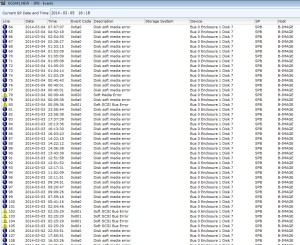
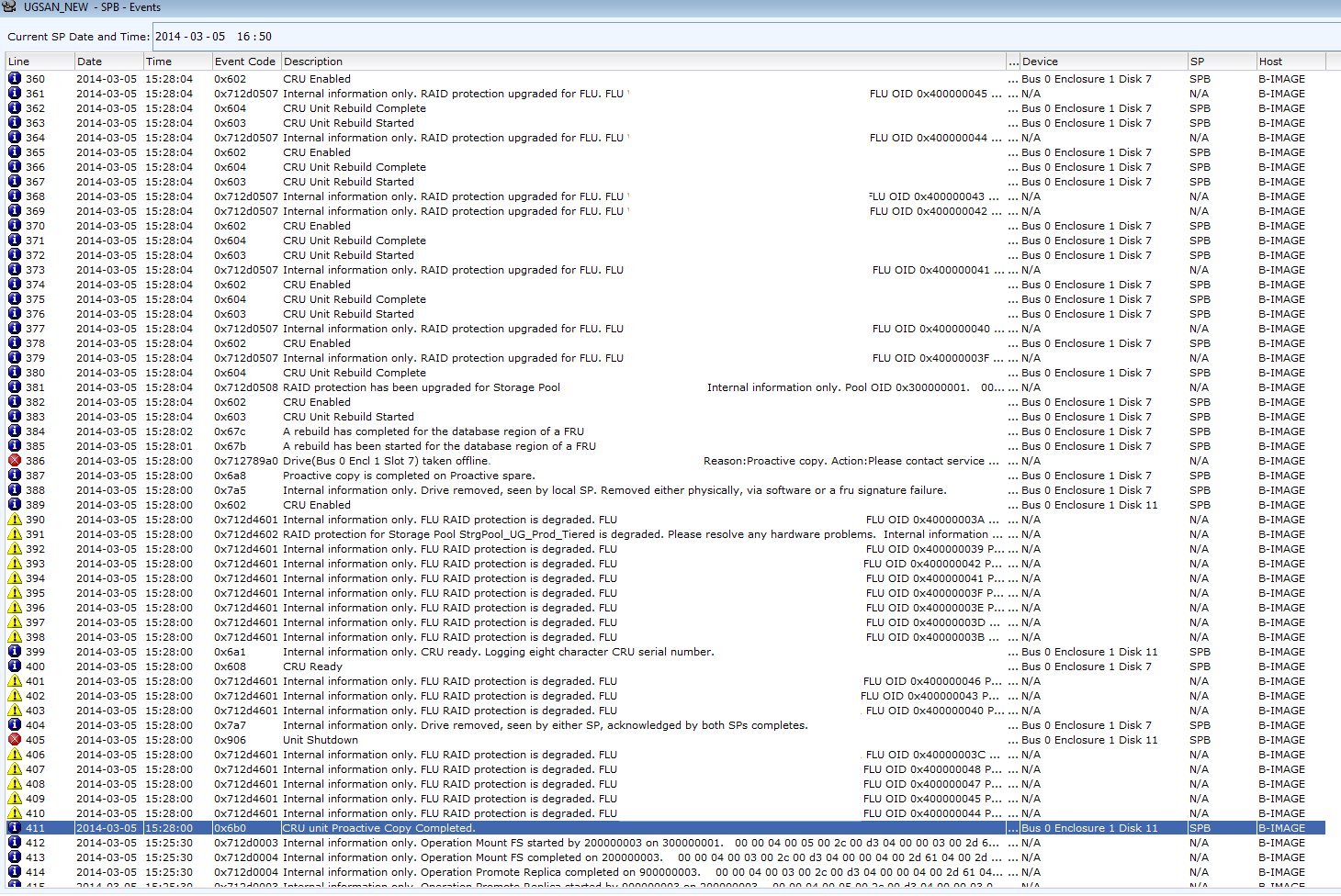
Notice that the majority of errors showed up as informational and not warning or critical, meaning the array will not indicate to anyone that this drive is about to fail, yeesh.
Note also that all the errors occur on the same disk, Bus 0 Enclosure 1 Disk 7, a NLSAS 2TB drive in my environment.
Event codes included 0x6a0, 0x820, and 0x801 with descriptions of disk soft media error, soft scsi bus error, and soft media error. My suggestion is to filter only on description, and do searches for “error” to find all the messages.
Reviewing the disks within the navisphere GUI showed that no disks were faulted, the dashboard showed no errors, and the hot spare was not in use, meaning the array did not believe the drive should be failed yet.
Time to be proactive…
I opened a case with EMC support, and sent them screenshots of the SP event logs, and SPCollects from both SPA and SPB, and noted that the error occurred on the same drive over 100 times in one day. The support representative immediately requested I do a proactive copy to the hot spare disk, and ordered a replacement disk sent to me.
A proactive copy is preferred because instead of requiring the array to rebuild the RAID array to a new disk (and endure the performance degradation inherent in this procedure), it copies the data from one disk to another, then tells the RAID array to use the hot spare disk, then disables the failing disk, skipping the rebuild process altogether and hence no RAID rebuild performance degradation.
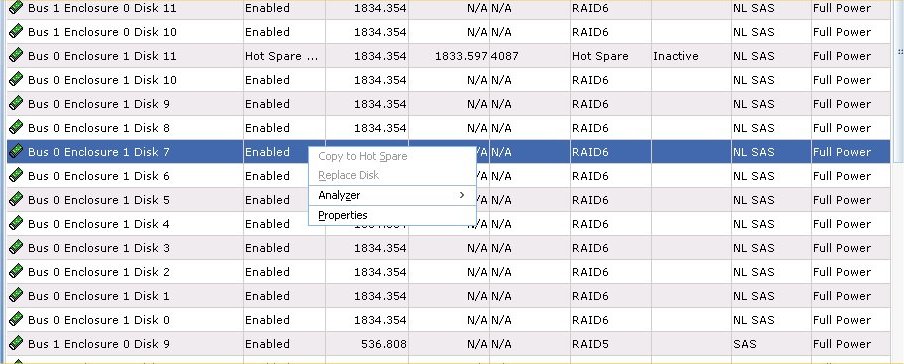
I first tried to do the proactive copy from the navisphere gui without success, below.
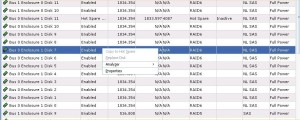
Note the option to copy is greyed out. Apparently VNXs new mixed RAID storage pools prevents this option from being used, so I moved onto the CLI.
Passing the command
naviseccli -Address <SP IP address> -User <user> -Password <password> -Scope 0 copytohotspare 0_1_7 -initiate
(where 0_1_7 is the failing disk) worked correctly, starting the proactive copy from the failing disk to the hotspare of the same type.
Checking progress of the proactive copy
Now to check progress of the copy…
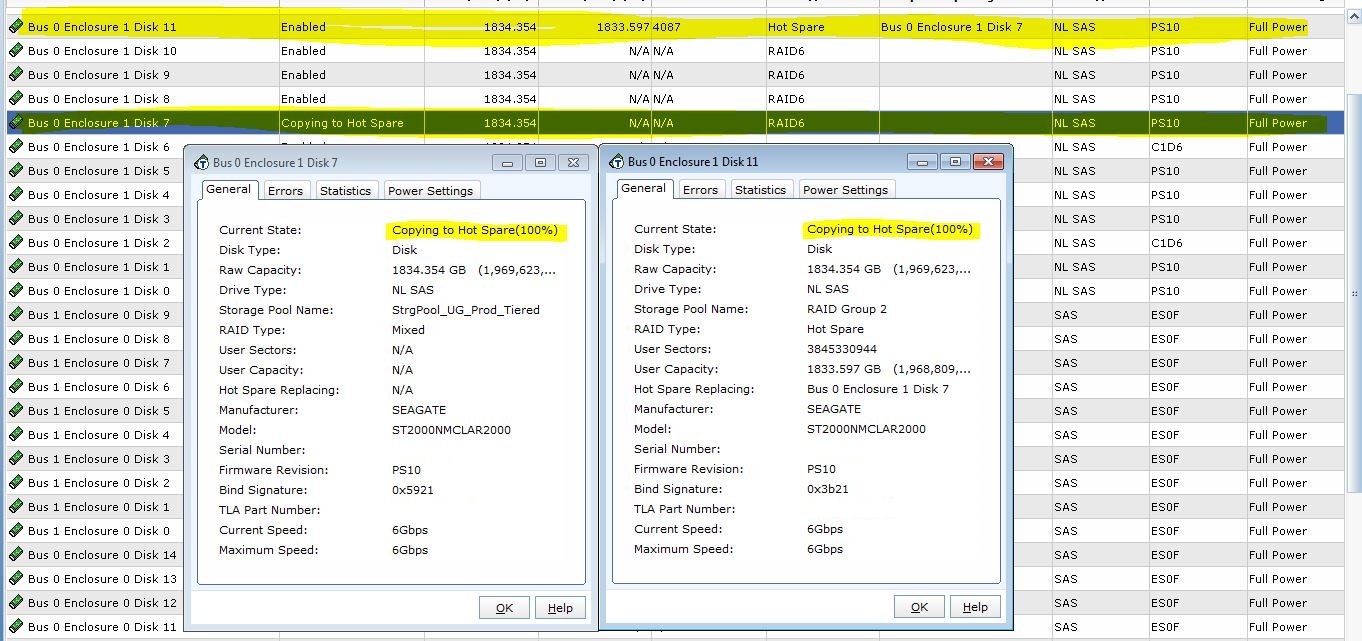
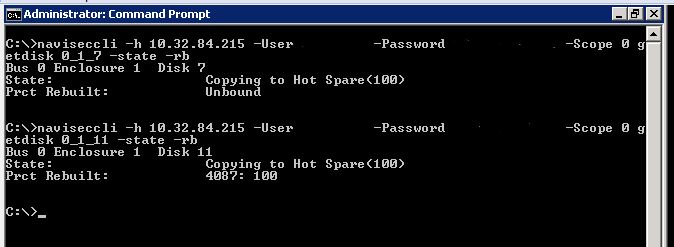
First I tried looking at the disks in the GUI
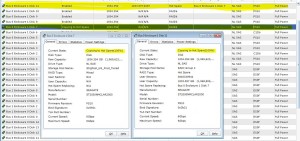
The disk state is listed as “Copying to Hot Spare(100%)”. Hmm, 100% doesn’t seem right, I just started this procedure. (Looking at the RAID LUN within the GUI showed the state as “transitioning” without any progress indicators)
Then I tried through the CLI
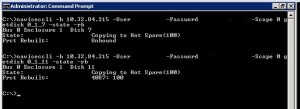
Well that also doesn’t look right, either. I continued on looking at SPCollect logs, SP event logs, and looking all over the Internet, including the EMC community forums, without finding any answers. (running getlun on the RAID LUN from the CLI didn’t show any progress indicators also)
Update: I figured out a way to gauge progress, though a bit crude. See the update at the bottom.
Eventually after 19 hours (NLSAS 2TB) the process completed, throwing event logs 0x6b0, 0x604, 0x67d, 0x6a8, 0x67c, 0x7a7, 0x6ab0 along with many others indicating it had marked the failing drive as failed as expected.
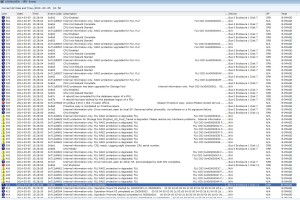
Complete list of event logs thrown as part of the proactive copy completion:
0x6b0, 0x712d4601, 0x906, 0x7a7, 0x608, 0x6a1, 0x602, 0x7a5, 0x6a8, 0x712789a0, 0x67b, 0x67c, 0x603, 0x602, 0x712d0508, 0x604, 0x712d0507, 0x2580, 0x906, 0x7a6, 0x799, 0x712d4602, 0x712d4601, 0x67d, 0x7400, 0x740a, 0x2580and probably some others I missed.
At this point I gave the EMC CE a call and scheduled replacement of the drive. Once the replacement drive is in place, the array should copy the information on the hot spare back to the replacement drive, then mark the hot spare drive as available again.
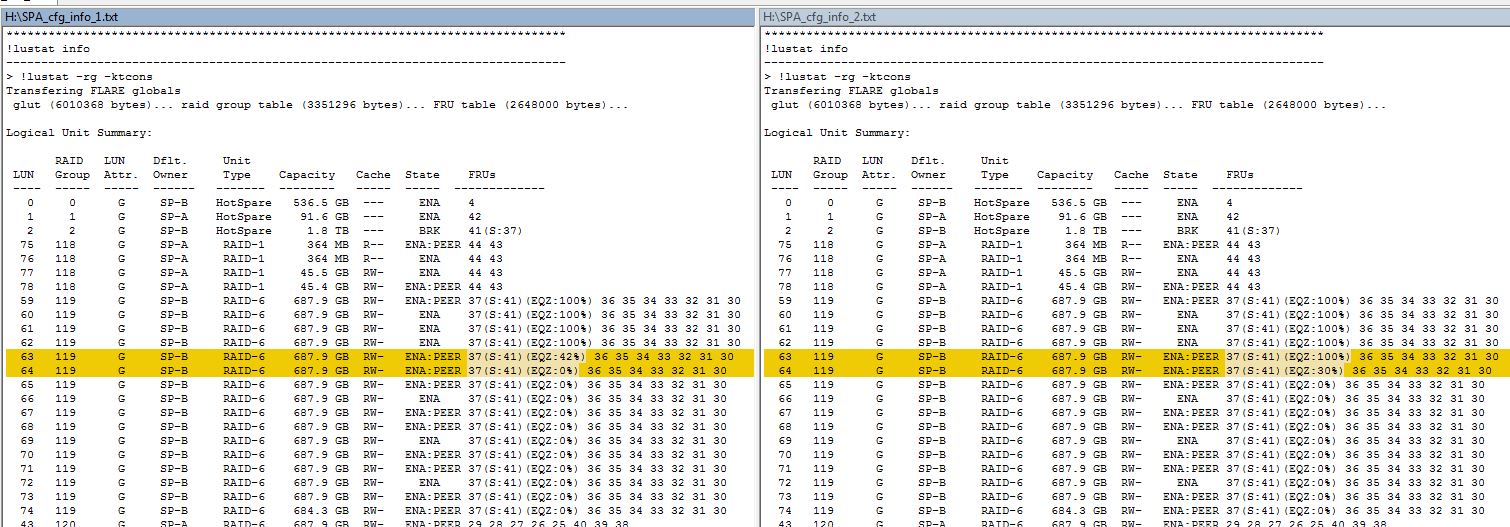
Update: It appears a progress indicator of sorts is included in the lustat command in the SPCollect logs. By running SPCollects over and over again I can gauge the progress of proactive copies and equalizations when the drive is replaced.
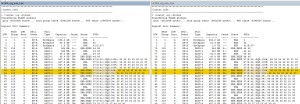
This information is contained within the SPCollect zip file, within the *_sus zip file, within the SPx_cfg_info.txt file. By looking at the EQZ percentage, I can gauge roughly when it will finish, and more importantly that the equalization or proactive copy is progressing.
Update: I came across a new EMC article today that may have a command that will work to gauge progress better. I have not attempted it myself yet.
From:
https://community.emc.com/docs/DOC-7962